Warum Machine Learning ohne MLOps oft nicht produktionsreif wird
Viele Machine-Learning-Projekte starten mit einem vielversprechenden Prototyp: Ein Modell wird trainiert, erste Metriken sehen gut aus und der fachliche Nutzen scheint greifbar. Die eigentliche Herausforderung beginnt jedoch häufig erst danach. Ein produktives ML-System muss nicht nur einmal trainiert werden, sondern dauerhaft zuverlässig funktionieren. Es muss nachvollziehbar versioniert, sicher bereitgestellt, kontinuierlich überwacht und bei Bedarf aktualisiert werden.
Genau hier setzt MLOps, also Machine Learning Operations, an. MLOps verbindet Prinzipien aus DevOps, Data Engineering und Cloud Operations mit den besonderen Anforderungen von Machine-Learning-Systemen. Während klassische Software primär aus Code und Infrastruktur besteht, kommen bei ML-Systemen zusätzliche Dimensionen hinzu: Trainingsdaten, Features, Modellartefakte, Experimente, Metriken, Modellversionen und potenzielle Veränderungen der Datenverteilung im laufenden Betrieb.
Sculley et al. (2015) zeigen, dass ML-Systeme besondere technische Schulden erzeugen können, wenn Datenabhängigkeiten, Modellverhalten, Pipeline-Logik und Monitoring nicht sauber beherrscht werden. ML-Prototypen wirken dadurch oft schneller produktionsreif, als sie tatsächlich sind. Ohne strukturierte Betriebsprozesse entstehen langfristig hohe Wartungskosten, schwer nachvollziehbare Modellentscheidungen und riskante manuelle Eingriffe.[1]
Produktionsreife ML-Systeme benötigen eigene Tests, Monitoring-Mechanismen und Qualitätskriterien. Es reicht also nicht aus, nur die Modellgüte im Notebook zu betrachten. Entscheidend ist, ob das gesamte System aus Daten, Training, Deployment und Betrieb robust funktioniert.[2][11]
Was MLOps in der Praxis bedeutet
MLOps beschreibt einen strukturierten Ansatz, um Machine-Learning-Modelle über ihren gesamten Lebenszyklus hinweg zu entwickeln, bereitzustellen, zu überwachen und weiterzuentwickeln. Ziel ist es, ML-Modelle nicht als isolierte Data-Science-Artefakte zu behandeln, sondern als produktive Softwarekomponenten, die in Unternehmensprozesse integriert werden.[12][13]
In der Praxis umfasst MLOps insbesondere folgende Aufgaben:
- Daten versionierenTrainingsdaten automatisiert bereitstellen und nachvollziehbar versionieren
- Reproduzierbares TrainingTrainingsläufe automatisiert und wiederholbar ausführen
- Experimente dokumentierenParameter, Metriken und Ergebnisse lückenlos festhalten
- Model RegistryModelle versioniert verwalten und kontrolliert freigeben
- CI/CD-DeploymentsBereitstellungen automatisiert und kontrolliert ausrollen
- MonitoringModell-, Daten- und Infrastrukturqualität überwachen
- RetrainingModelle bei Drift oder Qualitätsverlust neu trainieren
- Security & GovernanceZugriffe, Compliance und Nachvollziehbarkeit sicherstellen
Der zentrale Unterschied zu klassischen DevOps-Prozessen liegt darin, dass nicht nur Code bereitgestellt wird. In MLOps müssen auch Daten, Modelle, Trainingsumgebungen und Evaluationsmetriken kontrolliert werden. MLOps lässt sich daher auch als Verbindung aus ML-spezifischen Workflows und operativen DevOps-Praktiken beschreiben.[3][4][24]
Warum Microsoft Azure ein guter Ansatz für MLOps ist
Microsoft Azure bietet für MLOps einen starken Vorteil: Die Plattform verbindet Machine Learning, Datenintegration, Cloud-Infrastruktur, Security, DevOps und Monitoring in einem einheitlichen Ökosystem. Für Unternehmen, die bereits Microsoft-Technologien nutzen, lässt sich Azure Machine Learning daher gut in bestehende Cloud-, Daten- und Governance-Strukturen integrieren.[23]
Microsoft beschreibt die MLOps-v2-Architektur als modulares Muster mit mehreren Phasen: Data Estate, Administration & Setup, Model Development und Model Deployment. Die genaue Ausprägung hängt vom Szenario ab, aber die Grundlogik bleibt gleich: Daten, Modelle, Infrastruktur und Deployment-Prozesse werden über standardisierte Architekturbausteine verbunden.[5]
Ein weiterer Vorteil ist die Kombination mit bestehenden Azure-Diensten. Dazu gehören unter anderem Azure Machine Learning, Azure Data Lake Storage, Azure Data Factory, Azure DevOps, GitHub Actions, Azure Container Registry, Azure Key Vault, Azure Monitor, Log Analytics, Application Insights, Microsoft Entra ID und Azure Virtual Networks.
Damit eignet sich Azure besonders für Unternehmen, die ML nicht als isolierte Experimentierumgebung aufbauen möchten, sondern als Teil einer produktionsfähigen, sicheren und skalierbaren Enterprise-Architektur.
Zielarchitektur: MLOps in Microsoft Azure
Eine produktionsreife MLOps-Architektur in Microsoft Azure besteht aus mehreren Schichten. Sie beginnt bei der Infrastruktur, führt über Data-, ML- und Release-Pipelines bis hin zu Operations, Security und Governance. Der wichtigste Architekturgedanke ist dabei Modularität: Nicht jedes ML-Projekt benötigt dieselbe technische Ausprägung. Manche Use Cases benötigen nur ein kontrolliertes Modell-Deployment, andere erfordern regelmäßiges Retraining, komplexe Datenpipelines oder ein vollständiges End-to-End-MLOps-Setup.
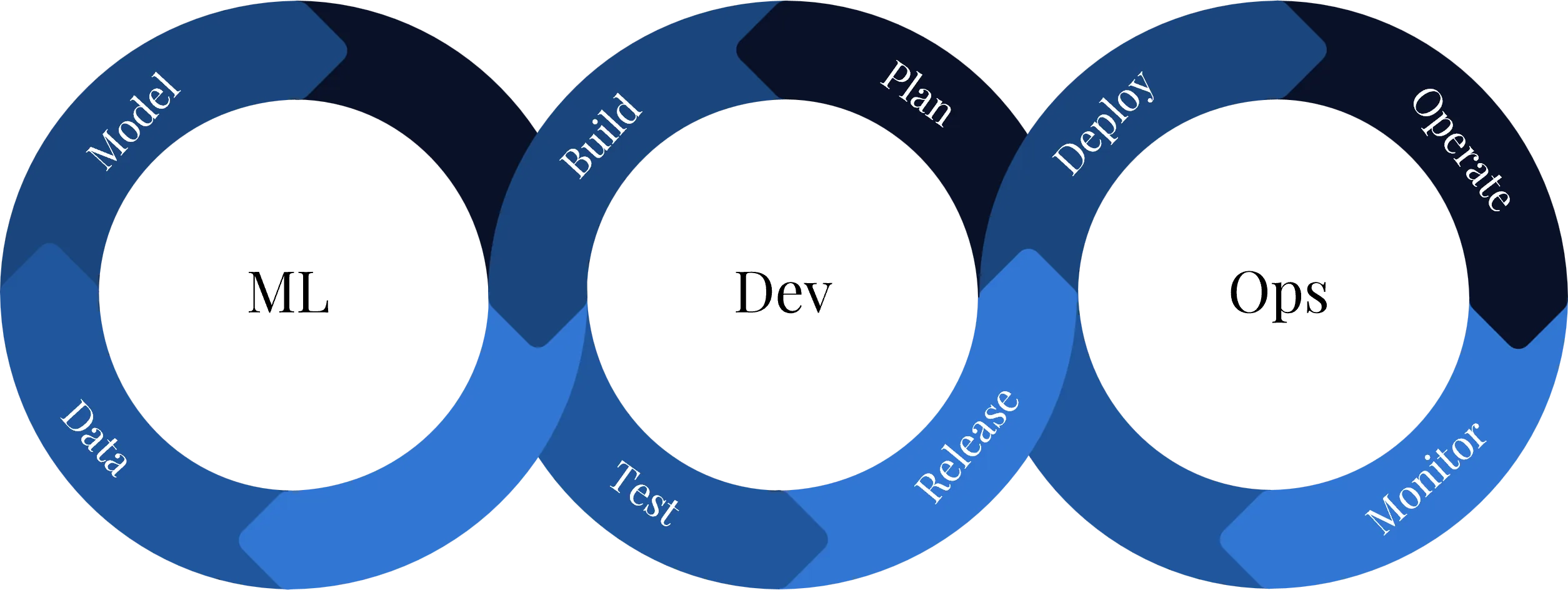
Diese Darstellung zeigt, dass MLOps kein linearer Prozess ist. Produktive ML-Systeme bilden vielmehr einen geschlossenen Kreislauf aus Datenbereitstellung, Training, Deployment, Monitoring und kontinuierlicher Verbesserung.
1. Infrastruktur
Die Infrastruktur bildet das technische Fundament der gesamten MLOps-Architektur. Sie stellt sicher, dass Daten, Trainingsprozesse, Modellartefakte, Deployments und Monitoring-Komponenten in einer kontrollierten Azure-Umgebung betrieben werden.
Eine typische Infrastruktur für MLOps auf Azure sieht so aus:
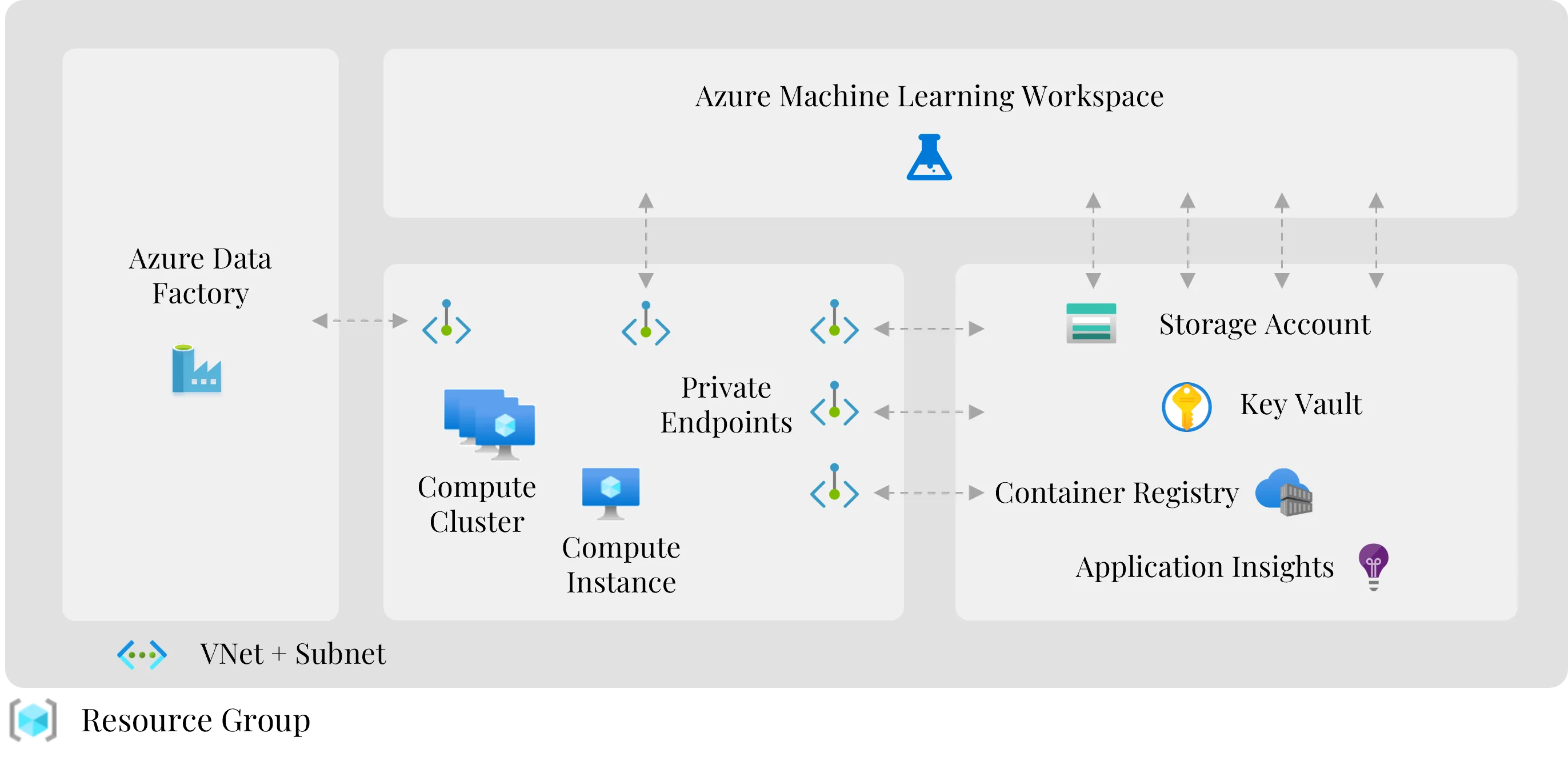
In produktiven ML-Umgebungen sollte Infrastruktur nicht manuell über das Azure Portal erstellt werden. Manuelle Konfigurationen sind schwer reproduzierbar, fehleranfällig und führen schnell zu Abweichungen zwischen Entwicklungs-, Test- und Produktionsumgebungen. Stattdessen sollte Infrastruktur als Code definiert und versioniert werden.
Microsoft beschreibt Bicep als deklarative Infrastructure-as-Code-Sprache für Azure-Ressourcen. Bicep-Dateien können wie Anwendungscode behandelt werden, wodurch Infrastrukturänderungen nachvollziehbar, wiederholbar und konsistenter deploybar werden. Für sichere Enterprise-Setups ist außerdem Netzwerkisolation relevant: Microsoft empfiehlt für Azure Machine Learning unter anderem die Absicherung des Workspaces und verbundener Ressourcen über Virtual Networks und Private Endpoints, sodass der Zugriff auf Storage, Container Registry, Key Vault und andere Dienste kontrollierbar bleibt.[10][21]
2. Machine Learning Pipelines
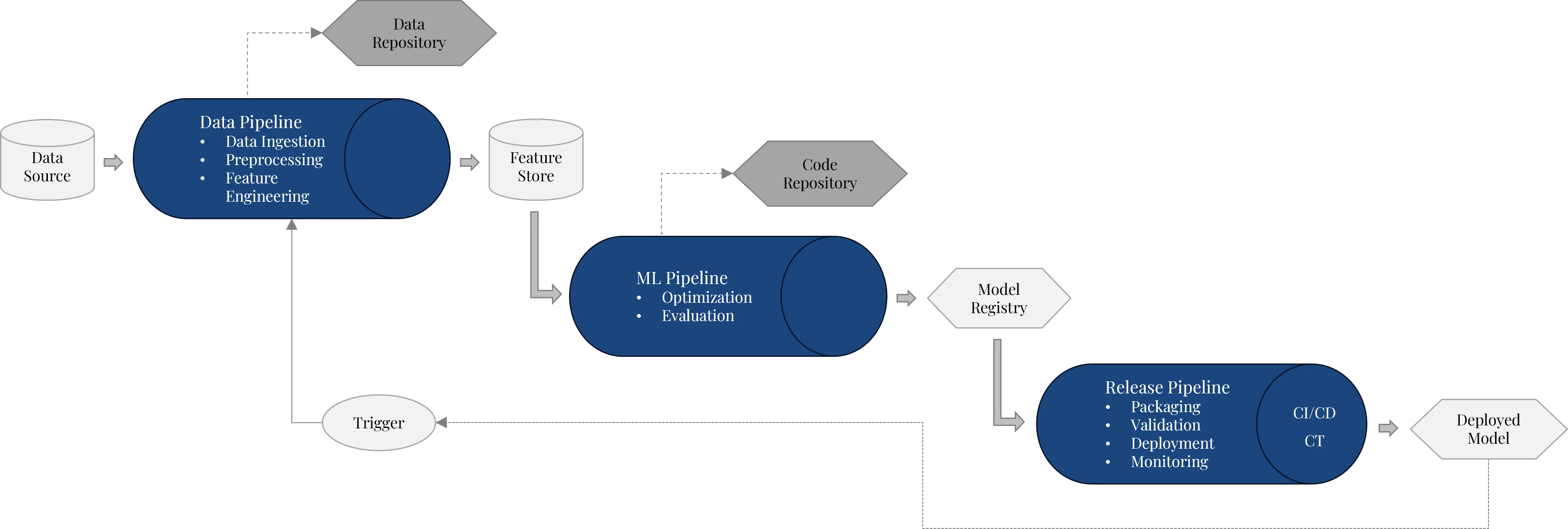
Auf der Infrastruktur setzen die eigentlichen ML-Prozesse auf. Diese lassen sich in drei Pipeline-Typen gliedern: Data Pipeline, ML Pipeline und Release Pipeline. Zusammen bilden sie den operativen Kern einer MLOps-Architektur.
Der Vorteil dieser Trennung liegt darin, dass jeder Teilprozess eigenständig entwickelt, getestet, versioniert und automatisiert werden kann. Gleichzeitig können die Pipelines miteinander verbunden werden, sodass ein durchgängiger Prozess vom Rohdatum bis zum produktiven Modell entsteht.
2.1 Data Pipeline: Daten zuverlässig bereitstellen
Die Data Pipeline sorgt dafür, dass Rohdaten aus unterschiedlichen Quellen automatisiert in eine für Machine Learning nutzbare Form überführt werden. Dazu gehören Datenaufnahme, Validierung, Transformation, Bereinigung, Preprocessing und Feature Engineering.
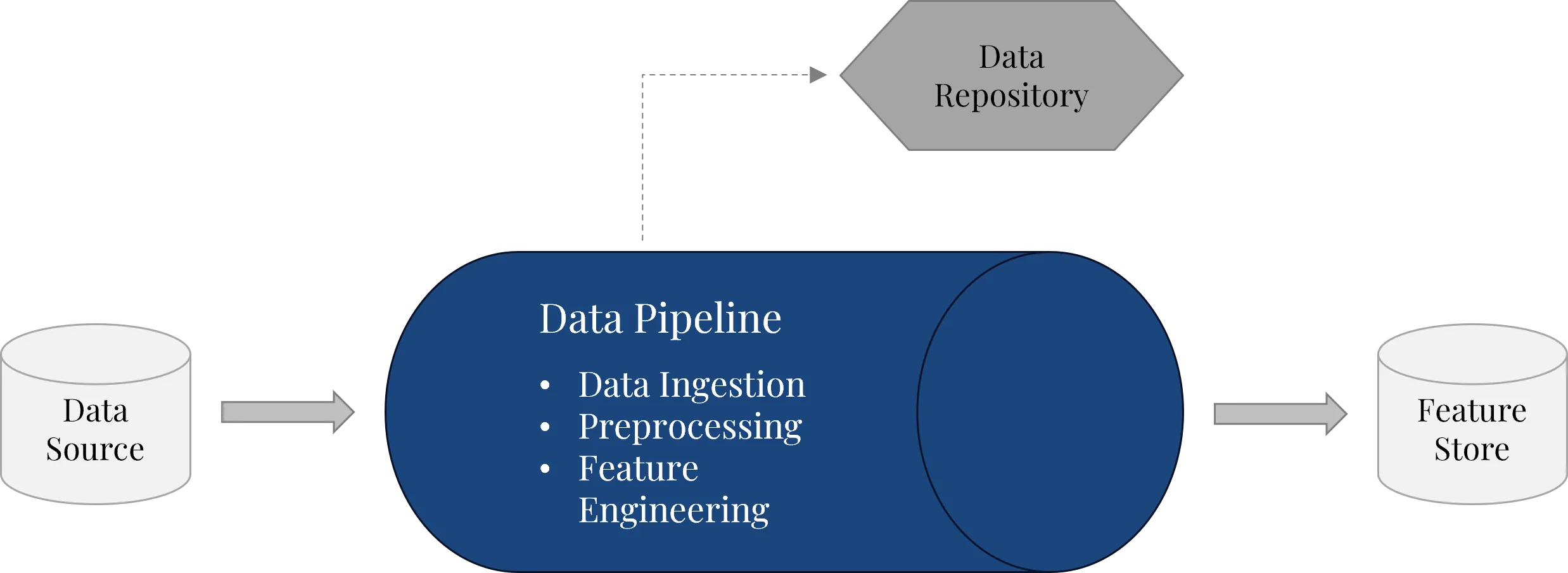
In Microsoft Azure kann eine Data Pipeline je nach Ausgangslage mit unterschiedlichen Diensten umgesetzt werden. Häufige Optionen sind Azure Data Factory, Microsoft Fabric Data Factory, Azure Synapse Pipelines oder Azure Databricks. Welche Lösung sinnvoll ist, hängt von Datenvolumen, Datenquellen, Transformationslogik, vorhandener Datenplattform und Betriebsanforderungen ab. Technisch sollte eine Data Pipeline drei Anforderungen erfüllen: Sie muss wiederholbar, versionierbar und umgebungsfähig sein.
- Wiederholbar: Trainingsdaten sollten nicht manuell exportiert, lokal angepasst und wieder hochgeladen werden. Stattdessen ist klar definiert, welche Daten aus welchen Quellen geladen und wie sie transformiert werden.
- Versionierbar: Änderungen an Datenlogik, Transformationen und Pipeline-Konfigurationen sollten über Git nachvollziehbar sein.
- Umgebungsfähig: Entwicklungs-, Test- und Produktionsumgebungen benötigen häufig unterschiedliche Parameter, etwa für Storage Accounts, Datenbankverbindungen oder Secrets.
Azure Machine Learning unterstützt diesen Ansatz durch sogenannte Data Assets. Diese verweisen auf Datenquellen und speichern Metadaten, ohne die Daten zwingend zu kopieren. Dadurch können Datenquellen über versionierte Referenzen genutzt werden, was Reproduzierbarkeit und Nachvollziehbarkeit verbessert. Wenn Azure Data Factory eingesetzt wird, sollte auch die Data-Pipeline-Logik in einen CI/CD-Prozess eingebunden werden, um Pipelines, Datasets, Data Flows und weitere Artefakte kontrolliert von Entwicklungs- in Test- und Produktionsumgebungen zu übertragen.[9][19]
2.2 ML Pipeline: Training, Experimente und Evaluation automatisieren
Die ML Pipeline übernimmt den eigentlichen Machine-Learning-Prozess. Sie nutzt die bereitgestellten Daten oder Features, trainiert Modelle, bewertet deren Qualität und speichert geeignete Modellversionen für spätere Deployments.[17][20]
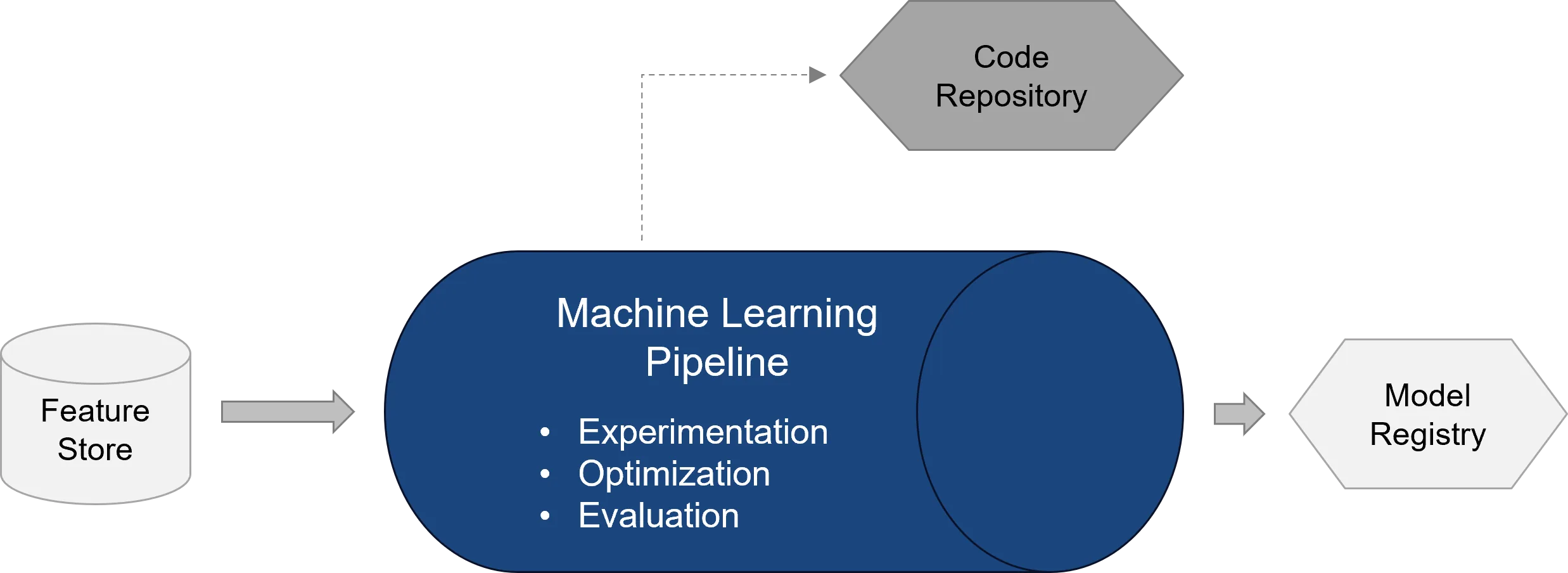
Typische Schritte einer ML Pipeline sind:
- Laden einer definierten Datenversion
- Ausführen von Preprocessing- oder Feature-Schritten
- Training eines oder mehrerer Modelle
- Hyperparameter-Tuning
- Evaluation anhand technischer und fachlicher Metriken
- Vergleich mit bestehenden Modellversionen
- Registrierung des besten Modells in der Model Registry
Azure Machine Learning unterstützt solche Abläufe über Pipelines, Jobs, Komponenten, Environments und Compute-Ressourcen. Pipelines können mit der Azure ML CLI, dem Python SDK oder über das Azure Machine Learning Studio erstellt werden. Komponenten verbessern dabei die Wiederverwendbarkeit und Flexibilität von ML-Pipelines.
Eine gute ML Pipeline sollte nicht nur ein Modell trainieren, sondern auch entscheiden können, ob dieses Modell überhaupt deploymentfähig ist. Dafür werden technische Metriken wie Accuracy, Precision, Recall, F1-Score oder RMSE mit fachlichen Mindestanforderungen kombiniert. Je nach Use Case können zusätzlich Fairness-, Robustheits- oder Stabilitätsmetriken relevant sein.
Ein zentraler Bestandteil ist die Model Registry. Sie bildet die Schnittstelle zwischen ML Pipeline und Release Pipeline. Nach Training und Evaluation wird ein Modell nicht als lose Datei gespeichert, sondern als versioniertes Artefakt registriert. Die Registry hält fest, welche Modellversion existiert, welche Metriken erreicht wurden und welche Metadaten mit dem Modell verbunden sind. Azure Machine Learning Registries ermöglichen außerdem die Wiederverwendung und gemeinsame Nutzung von Modellen, Komponenten und Environments über mehrere Workspaces hinweg.
2.3 Release Pipeline: Modelle kontrolliert bereitstellen
Die Release Pipeline überführt ein freigegebenes Modell aus der Model Registry in eine produktive Umgebung. Sie ist damit die Brücke zwischen Modellentwicklung und operativem Betrieb.
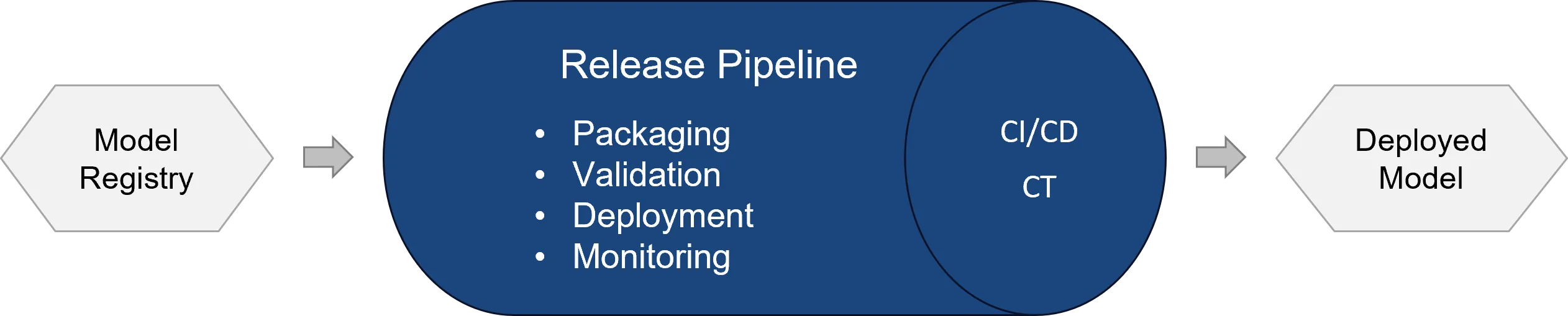
Typische Aufgaben der Release Pipeline sind:
- Auswahl einer freigegebenen Modellversion
- Paketierung des Modells inklusive Abhängigkeiten
- Definition oder Wiederverwendung eines Azure-ML-Environments
- Erstellung oder Aktualisierung eines Endpoints
- Ausführung von Smoke Tests oder Test-Inferenz
- Deployment in Test- oder Produktionsumgebung
- Freigabeprozess mit Approval Gates
- Rollback im Fehlerfall
In Azure Machine Learning können Modelle unter anderem über Managed Online Endpoints oder Batch Endpoints bereitgestellt werden. Managed Online Endpoints eignen sich für Echtzeit-Inferenz über HTTPS-Endpunkte und werden von Azure vollständig verwaltet – inklusive Infrastruktur, Skalierung, Sicherheit und Überwachung. Batch Endpoints eignen sich dagegen für größere, zeitversetzte Vorhersageläufe, beispielsweise wenn regelmäßig Prognosen für viele Datensätze erzeugt und anschließend in einem Data Warehouse, Data Lake oder BI-System weiterverarbeitet werden.[8]
Eine professionelle Release Pipeline sollte fachliche Modelllogik und operative Deployment-Logik klar trennen. Die Modelllogik liegt beispielsweise in Trainingscode, Feature Engineering und der scoring_file.py. Die operative Logik liegt in YAML-Dateien, Environment-Definitionen, Endpoint-Konfigurationen, Pipeline-Dateien und Deployment-Parametern. Diese Trennung macht den Prozess wartbarer: Data Scientists können an Modellen und Features arbeiten, während MLOps Engineers Deployment, Infrastruktur, Security und Automatisierung standardisieren.
3. Operations, Security und Governance
Nach dem Deployment beginnt der eigentliche Betrieb. Ein produktives ML-System muss nicht nur verfügbar sein, sondern kontinuierlich überwacht, abgesichert und kontrolliert weiterentwickelt werden.
Operations umfasst insbesondere:
- Monitoring von Endpoints, Latenzen, Fehlerquoten und Ressourcennutzung
- Überwachung von Modellmetriken
- Erkennung von Data Drift und Prediction Drift
- Überwachung der Datenqualität
- Kostenkontrolle und Alerting
- Retraining-Trigger
- Dokumentation und regelmäßige Reviews
Azure Machine Learning bietet Model Monitoring mit integrierten Signalen für tabellarische Daten, darunter Data Drift, Prediction Drift, Datenqualität, Feature Attribution Drift und Modellperformance. Für Online Endpoints kann Azure Machine Learning Produktions-Inferenzdaten automatisch erfassen und für kontinuierliches Monitoring verwenden.[7]
Security und Governance sollten nicht nachträglich ergänzt werden, sondern Teil der Architektur sein. Dazu gehören rollenbasierte Zugriffskontrolle, Managed Identities, sichere Secret-Verwaltung, Verschlüsselung, Netzwerkisolation, Logging, Auditierbarkeit und klare Freigabeprozesse. Managed Identities sind besonders wichtig, weil Compute-Ressourcen dadurch ohne hart codierte Zugangsdaten auf andere Azure-Dienste zugreifen können – etwa um Verbindungsinformationen aus Key Vault abzurufen oder Docker Images aus Azure Container Registry zu ziehen. Damit wird MLOps nicht nur zu einem technischen Automatisierungsansatz, sondern zu einem Governance-Modell für produktive KI-Systeme.[22]
Technische Umsetzung: Wie eine Azure-MLOps-Pipeline konkret aufgebaut wird
Nachdem die Zielarchitektur definiert ist, stellt sich die praktische Frage: Wie lässt sich eine solche MLOps-Struktur konkret umsetzen? Eine robuste technische Umsetzung verfolgt drei Ziele. Erstens sollen wiederkehrende Aufgaben automatisiert werden. Zweitens sollen Infrastruktur, Datenlogik, Trainingscode und Deployments versioniert sein. Drittens soll der Prozess so modular bleiben, dass unterschiedliche ML-Use-Cases nicht in eine starre Architektur gezwungen werden.
1. Repository-Struktur
Ein sinnvoller Startpunkt ist eine klare Repository-Struktur. Je nach Teamgröße kann diese als Monorepo oder als getrennte Repository-Landschaft aufgebaut werden. Eine beispielhafte Struktur kann so aussehen:
Diese Struktur trennt vier Verantwortungsbereiche: Infrastruktur, Datenintegration, Training und Deployment. Dadurch können einzelne Komponenten unabhängig voneinander weiterentwickelt werden, während der Gesamtprozess weiterhin standardisiert bleibt.
Den vollständigen, lauffähigen Beispielcode stellen wir in zwei offenen Repositories bereit – einmal für die Infrastruktur und einmal für die Pipelines:
smiit-GmbH/azure-iac-with-bicepInfrastructure as Code für Azure mit Bicep – Workspace, Storage, Container Registry, Key Vault, Compute und Netzwerk reproduzierbar bereitstellen.smiit-GmbH/azure-mlopsData-, ML- und Release-Pipeline für Azure Machine Learning inklusive CI/CD-Deployment.2. Infrastructure as Code mit Bicep oder Terraform
Die Infrastruktur sollte automatisiert bereitgestellt werden. Dazu zählen typischerweise Resource Group, Azure Machine Learning Workspace, Storage Account oder Data Lake, Azure Container Registry, Azure Key Vault, Application Insights, Log Analytics Workspace, Compute Cluster, Managed Identities, Private Endpoints und Netzwerkregeln.
Bicep eignet sich besonders gut, wenn Unternehmen stark im Azure-Ökosystem arbeiten. Die Syntax ist kompakter als klassische ARM Templates und bleibt trotzdem vollständig kompatibel mit Azure Resource Manager, da Bicep während des Deployments in ARM JSON umgewandelt wird. Ein typischer IaC-Prozess sieht so aus:
- 1Commit an Infrastrukturdateien
- 2Pull Request
- 3Automatische Validierung
- 4Deployment in Entwicklungsumgebung
- 5Optionales Approval
- 6Deployment in Testumgebung
- 7Optionales Approval
- 8Deployment in Produktionsumgebung
Der Vorteil liegt nicht nur in der Automatisierung, sondern auch in der Nachvollziehbarkeit. Jede Infrastrukturänderung ist versioniert, überprüfbar und im Fehlerfall leichter rückgängig zu machen.
3. CI/CD-Flow für Data Pipelines
Wenn Azure Data Factory oder Fabric Data Factory eingesetzt wird, sollte die Data Pipeline ebenfalls über CI/CD bereitgestellt werden. Dabei werden Pipeline-Definitionen, Datasets, Linked Services und Trigger nicht manuell in jeder Umgebung angepasst, sondern kontrolliert promoted.
- 1Feature Branch
- 2Änderung an Data-Pipeline-Logik
- 3Pull Request
- 4Validierung der Pipeline-Artefakte
- 5Export als ARM Template
- 6Deployment in Dev
- 7Deployment in Test
- 8Deployment in Prod
In produktiven Umgebungen ist zusätzlich wichtig, Trigger kontrolliert zu behandeln. Vor einem Deployment sollten aktive Trigger gestoppt und nach erfolgreichem Deployment wieder gestartet werden. Microsoft stellt dafür Beispielskripte für Pre- und Post-Deployment-Schritte bereit.
4. CI/CD-Flow für ML Pipelines
Die ML Pipeline sollte ebenfalls automatisiert ausführbar sein. Der Prozess beginnt meist mit einer Änderung am Trainingscode, an einer Komponente oder an der Pipeline-Konfiguration.
- 1Commit an Trainingscode oder Pipeline-YAML
- 2Pull Request
- 3Linting und Tests
- 4Validierung der Azure-ML-Konfigurationen
- 5Ausführung der Trainingspipeline
- 6Evaluation der Modellmetriken
- 7Registrierung des Modells
- 8Tagging der Modellversion
Azure Machine Learning unterstützt YAML-basierte Konfigurationen für Jobs und Pipelines: Azure-ML-Entitäten können über schematisierte YAML-Dateien definiert und über die Azure ML CLI erstellt werden. Der Vorteil liegt darin, dass Pipeline-Definitionen wie Code behandelt werden können – Änderungen laufen über Pull Requests, können automatisch validiert und später reproduzierbar ausgeführt werden. Eine ML Pipeline sollte außerdem nicht jedes Modell automatisch produktiv setzen, sondern eine Modellversion nur dann registrieren oder zur Freigabe markieren, wenn definierte Qualitätskriterien erfüllt sind.[18]
5. Release Pipeline für Online- oder Batch-Deployment
Die Release Pipeline übernimmt das kontrollierte Deployment eines registrierten Modells. Dabei werden Modellversion, Environment, Endpoint-Konfiguration und Deployment-Parameter zusammengeführt. Für einen Online Endpoint werden typischerweise registriertes Modell, scoring_file.py, Environment oder Docker Image, Endpoint- und Deployment-Konfiguration, Testdaten für Smoke Tests, Monitoring-Konfiguration und Approval-Regeln benötigt.
- 1Auswahl einer Modellversion aus der Registry
- 2Validierung der Deployment-Konfiguration
- 3Aufbau oder Auswahl des Environments
- 4Deployment in Testumgebung
- 5Smoke Test
- 6Approval
- 7Deployment in Produktion
- 8Monitoring aktivieren
Managed Online Endpoints eignen sich besonders dann, wenn ein Modell über eine API in Anwendungen, Workflows oder Plattformen integriert werden soll. Batch Endpoints sind sinnvoll, wenn Vorhersagen regelmäßig für große Datenmengen erzeugt werden, etwa für Forecasting, Scoring oder Klassifikationen im Hintergrund. Die Endpoint-Entscheidung sollte daher nicht technisch isoliert getroffen werden, sondern vom fachlichen Prozess abhängen: Muss das Ergebnis sofort verfügbar sein, spricht vieles für einen Online Endpoint. Wird das Ergebnis periodisch verarbeitet, ist ein Batch Endpoint oft einfacher und kosteneffizienter.
6. Monitoring und Retraining-Trigger
Der MLOps-Prozess endet nicht mit dem Deployment. Ein Modell kann im Laufe der Zeit schlechter werden, auch wenn sich am Code nichts geändert hat. Ursachen dafür können veränderte Datenverteilungen, neues Nutzerverhalten, geänderte Geschäftsprozesse oder externe Marktbedingungen sein. Deshalb sollte Monitoring mehrere Ebenen abdecken: technische Verfügbarkeit, Latenz und Fehlerquoten, Ressourcennutzung und Kosten, Datenqualität, Data Drift, Prediction Drift, Modellperformance und fachliche Ergebnisqualität.
Azure Machine Learning Model Monitoring unterstützt integrierte Signale wie Data Drift, Prediction Drift, Datenqualität und Modellperformance. Damit lassen sich Veränderungen erkennen, bevor sie zu größeren fachlichen Problemen führen. Ein vollständiger MLOps-Kreislauf kann so aussehen:
- 1Modell läuft produktiv
- 2Monitoring erkennt Drift oder Qualitätsverlust
- 3Alert wird ausgelöst
- 4Retraining wird manuell oder automatisch gestartet
- 5Neues Modell wird trainiert
- 6Modell wird evaluiert
- 7Modell wird registriert
- 8Release Pipeline deployed neue Version
Nicht jedes Unternehmen sollte von Beginn an vollautomatisches Retraining einsetzen. In vielen Fällen ist ein kontrollierter Human-in-the-loop-Prozess sinnvoller: Das Monitoring schlägt Alarm, ein Data-Science- oder MLOps-Team bewertet die Ursache und entscheidet anschließend über Retraining oder Deployment.
MLOps-Reifegrad: Nicht alles muss sofort vollständig automatisiert sein
Ein häufiger Fehler besteht darin, MLOps direkt als vollständige Enterprise-Plattform zu denken. Für viele Unternehmen ist ein schrittweiser Aufbau sinnvoller. Microsofts MLOps Maturity Model beschreibt MLOps als Reifeprozess und hilft dabei, Fähigkeiten schrittweise aufzubauen, den aktuellen Stand zu bewerten, Lücken zu identifizieren und den nächsten sinnvollen Entwicklungsschritt zu planen. Ein pragmatischer Reifegradpfad kann so aussehen:[6][14]
- 0
Level 0Manuelle ML-Prozesse
- 1
Level 1Versionierter Code und definierte Datenquellen
- 2
Level 2Automatisiertes Training
- 3
Level 3Standardisiertes Deployment
- 4
Level 4Monitoring und kontrolliertes Retraining
- 5
Level 5Vollständig integrierte MLOps-Plattform
Für viele Organisationen ist bereits ein großer Fortschritt erreicht, wenn Code, Daten, Modelle und Deployments sauber versioniert und manuelle Deployment-Schritte reduziert werden. Vollautomatisches Retraining, Canary Deployments oder organisationsweite Model Registries können später ergänzt werden.
Best Practices für Azure MLOps
- 1Modelle wie produktive Software behandelnEin Modell ist kein Notebook-Ergebnis, sondern ein produktives Artefakt mit Versionierung, Tests, Freigabeprozessen, Deployment-Strategien und Monitoring.
- 2Daten, Code und Modellversionen gemeinsam betrachtenReproduzierbarkeit entsteht nur, wenn klar ist, welche Datenversion, welcher Code-Stand, welche Parameter und welche Modellversion zusammengehören.
- 3Pipelines modular aufbauenData Pipeline, ML Pipeline und Release Pipeline sollten getrennt, aber integrierbar sein, damit Teams Komponenten wiederverwenden und Use Cases unterschiedlich stark automatisieren können.
- 4Infrastructure as Code konsequent nutzenCloud-Infrastruktur sollte nicht manuell gepflegt werden. IaC sorgt für konsistente Umgebungen, versionierte Änderungen und reproduzierbare Deployments.
- 5Security früh integrierenZugriffsrechte, Managed Identities, Key Vault, Private Endpoints, Logging und Netzwerkisolation gehören nicht erst kurz vor den Go-live.
- 6Monitoring auf Modell- und Datenebene erweiternCPU, RAM und Verfügbarkeit reichen bei ML-Systemen nicht aus – zusätzlich müssen Datenqualität, Drift, Modellmetriken und fachliche Ergebnisqualität überwacht werden.
- 7Standardisierung und Flexibilität ausbalancierenStandardisiert werden Infrastruktur, Deployment, Security, Monitoring und Governance; flexibel bleiben Modellwahl, Feature Engineering, fachliche Metriken und Use-Case-spezifische Logik.
Fazit: MLOps macht Machine Learning produktionsfähig
Machine Learning entfaltet seinen Wert nicht im Prototyp, sondern im produktiven Betrieb. Dafür reicht es nicht aus, ein gutes Modell zu trainieren. Unternehmen benötigen reproduzierbare Datenpipelines, automatisierte Trainingsprozesse, kontrollierte Deployments, versionierte Modelle, Monitoring, Security und Governance.
Microsoft Azure bietet dafür eine leistungsfähige Plattform. Azure Machine Learning, Azure DevOps, GitHub Actions, Bicep, Key Vault, Managed Identities, Azure Monitor und Azure Data Services lassen sich zu einer robusten MLOps-Architektur verbinden. Der entscheidende Erfolgsfaktor ist jedoch nicht nur die Technologie, sondern die richtige Architektur: Ein gutes MLOps-Framework standardisiert wiederkehrende operative Prozesse, ohne die fachliche Flexibilität einzelner ML-Projekte einzuschränken. So wird aus einzelnen ML-Prototypen eine skalierbare, sichere und wartbare Grundlage für produktive KI-Anwendungen.